Introduction
In my next few blog, I'll discuss sorting and searching in details.Sorting is the process of putting a group of items in specific order(increasing or decreasing order according to some linear relationship among the list of elements) whereas searching refers to finding an item with specified properties among a collection of items.Following figure shows the topics that I'll discuss one after another.

Linear Search
It is a very straight forward method where we compare each element of Array with the key, If the element is found,we announce that element is found or the location of the element in the array.Otherwise we print that element is not present in the list.
The worst case ( if the element is present at the end of the array or not present at all) and average case complexity of Linear search is proportional to the number of elements in the list,but best time complexity is O(1)(the key is present at the beginning of the array).The algorithm is best suited if the number of elements in the array is small.Advantages of linear search are ->
- It is easy to implement and understand.
- Unlike binary and ternary search ,it does not impose additional requirements.
The pseudo code for the algorithm is->
For each element in the Array:
if the item has the desired value,
stop the search and return the location.
I have already show you code for linear search in my previous blog
(http://binoykgec.blogspot.in/2013/06/analysis-of-time-complexity.html).That's why not presenting it again.
Elementary Sorts
Here I will discuss three sorting algorithms.They are
- Bubble Sort or Sink Sort.
- Selection Sort.
- Insertion sort.
Bubble Sort or Sink Sort
This technique is called Bubble sort or Sinking sort because the smaller values gradually "bubble" their way upward to the top of the array like air bubbles rising in water, while the larger values sink to the bottom of the array.
Pseudo code for the algorithm shown below:
procedure BubbleSort(A : Array of sortable items)
For i = 0 to length(A) - 2 :
For j = i+1 to length(A) - 1:
if A[i] > A[j] :
swap(A[i],A[j]).
end if
end For
end For.
Complexity Analysis:
In Worst,Average and Best,all three cases j runs for i+1 to end of the array.Hence the complexity in three cases is clearly O(N^2).
Explanation->
for i=0 j runs (N-1) times
for i=1 j runs (N-2) times
for i=2 j runs (N-3) times
......................................
......................................
......................................
......................................
for i=N-1 j runs 1 times
Hence Total cost =(N-1) + (N-2) + ..... + 2 + 1
=(N-1)*(N-1+1)/2
= N(N-1)/2
= O(N^2)
An Example:
Now let's see how the algorithm works on An array A.

(Each time the selected entries are marked with underline and swapped elements are highlighted).
1st pass ( i=0,j= 1 to 4)

2nd pass ( i=1,j= 2 to 4)
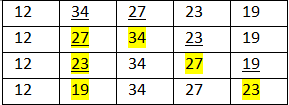
3rd pass ( i=2,j= 3 to 4)

4th pass (i = 3,j = 4 to 4)

Now the array is a sorted one after completion if the algorithm.

Here is C++ code for the above algorithm.
 |
| Bubble Sort |
A sample run is shown below.

That's all about Bubble Sort.In next blog, I'll explain two other elementary sorts.If you have any doubt,drop me a email at ernstbinoy@gmail.com.




